Tengo dos archivos A - nodes_to_delete y B - nodes_to_keep. Cada archivo tiene muchas líneas con identificadores numéricos.bash, Linux: establecer la diferencia entre dos archivos de texto
Quiero tener la lista de identificadores numéricos que están en nodes_to_delete pero NO en nodes_to_keep, p. alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
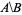{kind=link}
Hacerlo en una base de datos PostgreSQL es irrazonablemente lento. ¿Alguna forma ordenada de hacerlo en bash usando las herramientas CLI de Linux?
ACTUALIZACIÓN: Esto parece ser un trabajo Pythonic, pero los archivos son realmente, muy grandes. He resuelto algunos problemas similares usando uniq, sort y algunas técnicas de teoría de conjuntos. Esto fue aproximadamente dos o tres órdenes de magnitud más rápido que los equivalentes de la base de datos.
tengo curiosidad en cuanto a qué respuestas vendrán. Bash es un poco más segphault, administrador de sistemas, creo. Si hubieras dicho "en python" o "en PHP" o lo que sea, tus posibilidades habrían sido mejores :) – extraneon
Vi el título y estaba listo para criticar las inconsistencias de UI y los foros de ayuda de Holier-than-thou. Esto me decepcionó cuando leí la pregunta real. :( – aehiilrs