El método de fuerza bruta sería tratar de añadir cartas a cada índice disponibles usando una búsqueda en profundidad.
Por lo tanto, comenzando con 'a', hay dos lugares donde puede agregar una nueva letra. Delante o detrás de la 'a', representada por puntos debajo.
.a.
Si se agrega una 't', en la actualidad hay tres posiciones.
.a.t.
Usted puede tratar de añadir los 26 cartas a cada posición disponible. El diccionario en este caso puede ser una tabla hash simple. Si agrega una 'z' en el medio, obtendrá 'azt', que no estaría en la tabla hash, por lo que no continuará por esa ruta en la búsqueda.
Editar: el gráfico de Nick Johnson me hizo tener curiosidad sobre cómo sería un gráfico de todos los caminos máximos. Es una imagen de gran tamaño (1,6 MB) aquí:
http://www.michaelfogleman.com/static/images/word_graph.png
Editar: He aquí una implementación de Python. El enfoque de la fuerza bruta en realidad se ejecuta en un tiempo razonable (unos segundos, dependiendo de la letra de inicio).
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
Por supuesto, habrá muchos vínculos en la respuesta. Esto imprimirá los primeros N resultados, medidos por la longitud de la palabra final.
Salida para la letra de inicio 'a', utilizando el diccionario TWL06 Scrabble.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
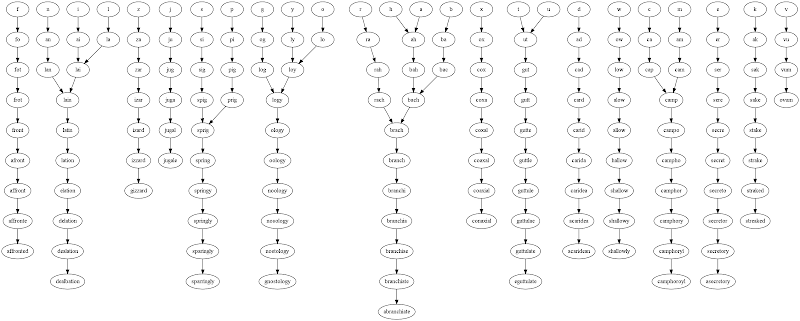
Y aquí están los resultados para cada letra inicial. Por supuesto, se hace una excepción que la letra de inicio simple no tiene que estar en el diccionario. Solo una palabra de 2 letras que se puede formar con ella.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
{kind=link}
Problema interesante. ¿Qué has intentado hasta ahora y dónde estás atrapado? –
Define "diccionario de palabras". ¿Es una tabla hash, un trie o qué? Si es un trie, una simple búsqueda DF funcionará. ¿Es un árbol de sufijos como sugieren las etiquetas? – IVlad
Suena como un problema de tarea, mal especificado. –