Tengo un programa que necesita calcular repetidamente el percentil aproximado (estadística de orden) de un conjunto de datos para eliminar valores atípicos antes del procesamiento posterior. Actualmente lo estoy haciendo ordenando la matriz de valores y seleccionando el elemento apropiado; esto es factible, pero es un problema notorio en los perfiles a pesar de ser una parte bastante menor del programa.Algoritmo rápido para calcular percentiles para eliminar valores atípicos
Más información:
- El conjunto de datos contiene del orden de hasta 100.000 números de punto flotante, y asume que es "razonablemente" distribuida - es poco probable que sea una duplicación ni enormes picos de densidad de cerca de concreto valores; y si por alguna extraña razón la distribución es impar, está bien que una aproximación sea menos precisa, ya que los datos probablemente estén en mal estado y el procesamiento sea dudoso. Sin embargo, los datos no son necesariamente distribuidos uniforme o uniformemente; es muy poco probable que sea degenerado.
- Una solución aproximada estaría bien, pero necesito entender cómo la aproximación introduce un error para garantizar que sea válida.
- Dado que el objetivo es eliminar valores atípicos, estoy calculando dos percentiles sobre los mismos datos en todo momento: p. uno al 95% y uno al 5%.
- La aplicación está en C# con cargas pesadas en C++; pseudocódigo o una biblioteca preexistente en cualquiera estaría bien.
- Una forma completamente diferente de eliminar valores atípicos también estaría bien, siempre que sea razonable.
- Actualización: Parece que estoy buscando un selection algorithm aproximado.
A pesar de todo esto se hace en un bucle, los datos es (ligeramente) diferente cada vez, así que no es fácil de reutilizar una estructura de datos como se hizo for this question.
implementado la solución
Usando el algoritmo de selección de Wikipedia como sugiere Gronim reduce esta parte del tiempo de ejecución en un factor 20.
Como no podía encontrar una aplicación C#, esto es lo que se le ocurrió. Es más rápido incluso para entradas pequeñas que Array.Sort; y en 1000 elementos es 25 veces más rápido.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI)/2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
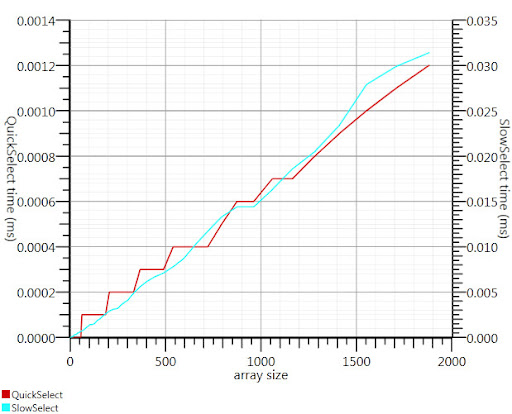
Gracias, Gronim, para mí apuntando en la dirección correcta!
Correcto, eso es lo que estaba buscando, ¡un algoritmo de selección! –