5
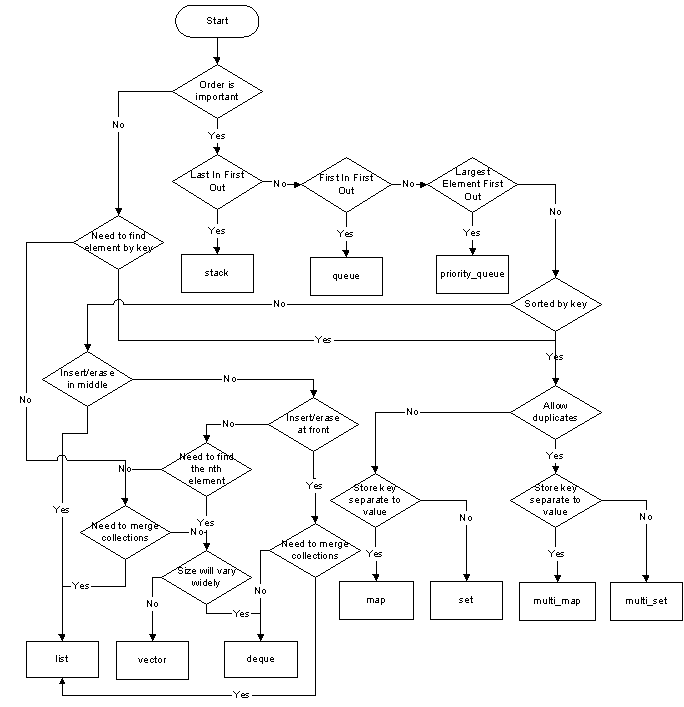
Quiero almacenar cadenas y emitir cada una con un número de identificación único (un índice estaría bien). Solo necesitaría una copia de cada cadena y necesito una búsqueda rápida. Compruebo si la cadena existe en la tabla con la suficiente frecuencia que noto un golpe de rendimiento. ¿Cuál es el mejor contenedor para usar para esto y cómo busco si la cadena existe?contenedor para la búsqueda rápida de nombres
{kind=link}
No utilice unordered_map en T1, que no tiene el método de reserva y si se inserta un montón de cadena durante la fase de inserción que van a tener una gran cantidad de refrito. –
También unordered_map para cadenas largas es peor que un estándar :: map –